Numpy
Introducing Numpy
numpy 배열
numpy는 과학계산을 수행하는 파이썬 핵심 패키지
주요 제공 기능
- N 차원 배열
- 원소별 연산(브로드캐스팅)
- 선형대수학 등 핵심 수학 연산
- C/C++, 포트란 코드 인터페이스 제공
numpy 공식 레퍼런스
- https://docs.scipy.org/doc/numpy/reference/
Python list vs numpy 배열
Python의 리스트는 거의 모든 종류의 객체를 담을 수 있어 유연하지만, 속도와 메모리 효율이 좋지 않다는 것이 단점
numpy의 배열은 한 행에 동일 형식의 원소를 저장
- Python의 리스트에 비해 유연성은 떨어지지만
- 빠른 연산과 메모리 효율에서 강점을 보인다
numpy의 사용
일반적으로 numpy는 np라는 별칭으로 줄여 임포트한다
numpy 배열 만들기
Python의 리스트를 이용한 생성
- 각 값들은 (양의 정수)튜플 형태로 인덱싱됨
- shape는 각 차원의 크기를 튜플로 반환
- np.ndim은 배열이 몇 차원인지 의미
- 다차원 배열을 만들기 위해서는 리스트를 중첩하여 생성

List 없이 array 만들기
- zeros() : 0으로 채워진 배열
- ones() : 1로 채워진 배열
- full() : 지정한 상수로 채워진 배열
- eye() : 단위 행렬 생성
- empty_like() : 주어진 배열과 동일한 shape를 가지며 비어 있는 배열 생성

범위 벡터의 생성
- arange() : 범위 값으로 배열 만들기
- linspace() : 선형 간격의 벡터 만들기
- logspace() : 로그 간격의 벡터 만들기

array의 타입
numpy의 array는 한 가지 타입만 담을 수 있다
- 데이터 타입을 지정하지 않으면 임의로 적절한 데이터 타입을 선택
- dtype으로 array의 타입을 체크할 수 있다
- array 생성시 dtype 옵션 파라미터로 데이터 타입을 강제할 수 있다
- astype() 메서드를 이용하면 다른 데이터타입으로 변경할 수 있다
numpy 자료형 참조 페이지 : https://docs.scipy.org/doc/numpy/reference/arrays.dtypes.html
Data type objects (dtype) — NumPy v1.17 Manual
Data type objects (dtype) A data type object (an instance of numpy.dtype class) describes how the bytes in the fixed-size block of memory corresponding to an array item should be interpreted. It describes the following aspects of the data: Type of the data
docs.scipy.org

array의 재구성
생성된 array는 다양한 형태로 변경될 수 있다
- reshape() : 배열을 다른 형태로 변경
- ravel() : 다차원 배열을 1차원 형태로 변경
- transpose() : 행렬의 전치. 열 <-> 행
- 간단히 T 속성을 사용해도 무방

array의 인덱싱과 슬라이싱
numpy의 array 인덱싱과 슬라이싱은 기본적으로는 파이썬의 인덱싱/슬라이싱 방식과 거의 동일하다
numpy의 array는 다차원인 경우가 많기 때문에 각 차원별 인덱스/슬라이스 범위를 잘 정해주어야 한다

조건적 인덱싱
- where() : 조건에 해당하는 인덱스를 추출
- delete() : 특정 인덱스 삭제

Boolean 배열 인덱싱
- 논리 연산을 수행하여 복수의 조건을 만족하는 인덱스를 추출해내는 방법
- numpy 배열 불린 연산에서는 &(and), |(or), ~(not) 연산자를 사용할 수 있다
- Boolean 배열 인덱싱 참조 : https://docs.scipy.org/doc/numpy/reference/arrays.indexing.html
Indexing — NumPy v1.17 Manual
Indexing ndarrays can be indexed using the standard Python x[obj] syntax, where x is the array and obj the selection. There are three kinds of indexing available: field access, basic slicing, advanced indexing. Which one occurs depends on obj. Note In Pyth
docs.scipy.org

배열 연산
- 기본적 수학 함수는 배열의 각 요소별로 동작
- 연산자를 이용 동작하거나 numpy 함수 모듈을 이용하여 동작함

numpy 행렬 곱
- *, multiply는 기본적으로 요소의 곱
- 벡터의 내적, 벡터와 행렬의 곱, 행렬곱을 위해서는 dot 함수 사용
- dot 메서드는 모듈 함수, 배열 객체의 인스턴스 양쪽 모두 사용 가능

array 연산 함수
- numpy는 배열 연산에 유용하게 사용되는 많은 함수를 제공
- 배열 연산 함수 참조 : https://docs.scipy.org/doc/numpy/reference/routines.math.html
Mathematical functions — NumPy v1.17 Manual
gcd(x1, x2, /[, out, where, casting, order, …]) Returns the greatest common divisor of |x1| and |x2|
docs.scipy.org

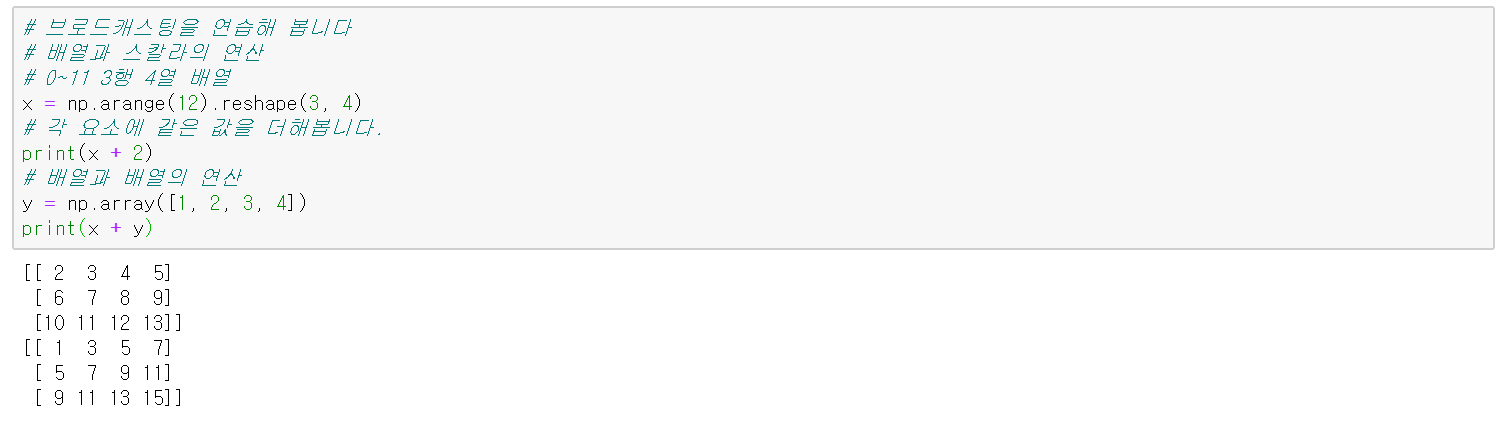
브로드캐스팅
- numpy에서 shape가 다른 배열 혹은 배열과 스칼라 사이의 산술 연산이 가능하도록 하는 매커니즘
- Universal Function이라고도 함
numpy 난수 발생
- 임의의 수가 필요할 때, 혹은 전체 데이터를 기반으로 샘플링을 하고자 할 때는 난수가 필요
- numpy의 난수 발생은 단순히 임의의 난수를 넘어 다양한 통계(분포:distribution) 기반의 샘플링을 위한 난수 기능을 다양하게 제공
- random 패키지 내에 위치
- 다양한 난수 메서드들
- randint() : 정수 난수 발생
- randn() : n차원 난수 발생
- binomial() : 이항분포
- hypergeometric() : 초기하분포
- poisson() : 포아송 분포
- normal() : 정규 분포
- standart_t() : t-분포
- uniform() : 균등분포
- f() : f-분포
- seed() : 재현 가능성(Reproductibility)을 위한 난수 초기값 설정

numpy 파일 저장/불러오기
numpy는 바이너리 형태로 저장 가능하며 저장된 데이터는 나중에 불러와 다시 사용할 수 있다
저장 메서드
- save() : npy(비압축) 형태로 저장
- savez() : npz(압축) 형태로 저장. 압축 과정을 거치므로 save 메서드에 비해 속도는 느리지만, 대용량의 데이터 저장엔 용량의 측면에서 유리
- 불러오기 메서드
- load()

